![]()
![]()
大数据在各行各业中应用广泛 没有什么能逃出你的掌心
大数据特点 数据量大 数据种类多 要求实时性强 主导气质无法掩盖

同时推出大数据hadoop
引领大数据行业风潮
网站后台维护
大型项目必选开发语言

大数据处理服务器开发
金融机构大数据应用

智能家居家电

银行管理系统
真实就业数据 震撼你的小心脏
无论按照工作经验还是市场本身的薪资变化趋势
大数据工程师都是一路高歌猛进,当之无愧的互联网贵族!










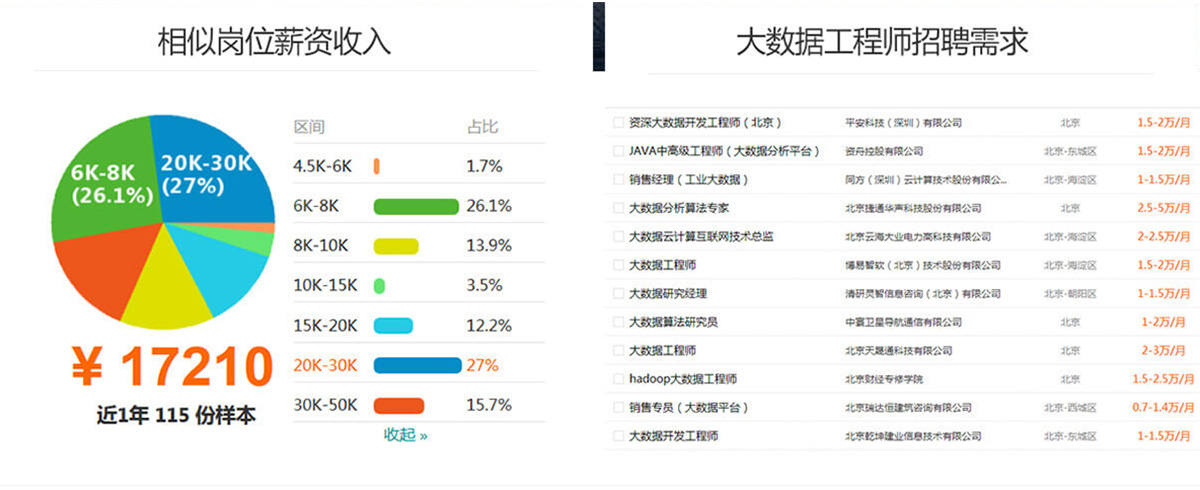
市场招聘条件分析
北京大数据工程师就业形势分析:招聘待遇,工资20000-29999占比最多,达35%。经验要求,3-5年工作经验要求的占比最多,达63%;学历要求,本科学历要求的占比最多,达66%。该数据仅供参考

以上数据来自百度搜索
我要入门潮流技能 颠覆性课程
拒绝用老掉牙的淘汰项目练手 要做就做前沿
覆盖大数据行业主流技术岗位,课程半年升级一次,紧跟市场与企业步伐
01 大数据入门基础课程
1.JavaSE
2.MySQL
3.JDBC
4.Linux
5.shell
6.HTML
7.CSS
8.JavaScript
9.JSP
10.Servlet
02 大数据Hadoop基础
1.大数据概论
2.Hadoop框架
3.HDFS分布式文件系统
4.MapReduce计算模型
5.全真实训项目
03 大数据离线分析
1.Hive数据仓库
2.Sqoop ETL工具
3.Azkaban工作流引擎
4.Ooize
5.Impala
6.全真实训项目
04 大数据实时计算
1.Zookeeper分布式协调系统
2.HBase分布式数据库
3.Redis数据库
4.mogDB数据库
5.Kudu列式存储系统
6.Storm实时数据处理平台
7.Kafka分布式发布订阅消息系统
8.Flume海量日志采集系统
9.全真实训综合项目
05 Spark数据计算
1.Scala
2.Spark
3RDD
4.Spark SQL
5. Streaming
6. Mahout
7.MLlib
8.GraphX
9.Spark R
10.Python
11.Alluxio
12.Python爬虫
13.ElasticSearch
14.Lucene

Hadoop基础实战项目
项目名称:搜狗搜索日志分析系统
数据体量:5000W+/日
硬件环境:Hadoop集群 12台
软件环境:Hadoop2.5.2+Hive1.2.1+MR+Oracle10g
项目描述:
搜狗每天产生大量的日志数据,从日志数据里面能提取到有用的数据包括每个用户的ID、浏览次数、月/日浏览频率、访问源、浏览内容等等,提取这些内容、统计数据分析每个用户行为,从而做出有利的决定。

大数据离线实战项目
项目名称:新浪微博数据分析系统
日均数据体量:3GB+
硬件环境:Hadoop集群 50台
软件环境:MapReduce+HBase0.98.9+Storm0.9.6+Hadoop2.5.2+Kafka2.10+Zooke
eper3.4.5+CentOS-6.5-X86
项目描述:
此次项目我们需要处理微博产生的数据,通过对数据的处理得到所需的数据,微博拥有大量的用户,大量的用户潜在的价值是巨大,怎么挖掘这些潜在的宝藏就是我们项目最直接的目的,为了能够实时的进行数据处理使用Storm流式计算系统,和HBase、Zookeeper、Kafka组成框架,对数据进行处理,当然这些都是建立在hadoop集群上实现的,底层的存储还是HDFS。
大数据实时全真项目
项目名称:网络流量流向异常账号统计项目
数据体量:每天1000亿,每秒峰值100 000
硬件环境:Hadoop集群 600台
软件环境:Hadoop2.5.2+Hive1.2.1+MR+Oracle10g
项目描述:
运营商骨干网上采集现网流量流向信息,根据这些原始信息检测账号是否存在异常,如果多个终端使用同一个宽带账号,超过一定阈值则触发报警机制,例如阈值为5时,同一个账号同时连接的终端数量不能超过该值,如果超过则报警。
Spark阶段项目
项目名称:京东网上商城数据统计分析平台
数据体量:5000W+/日
硬件环境:centos-6.5-x86 集群:spark standalone(Master-1,Worker-3)
软件环境:hadoop,spark,hive,mysql,idea,navicat,kafka,flume
每日处理的数据量:3GB
项目描述:
基于京东网上商城数据统计分析平台--该项目采用了目前大数据领域非常流行的技术——Spark。本项目使用了Spark技术生态栈中最常用的三个技术框架,Spark Core、Spark SQL和Spark Streaming,进行离线计算和实时计算业务模块的开发。实现了包括:统计和分析UV、PV、登录、留存、热门商品离线统计、广告流量实时统计3个业务模块。
大数据在各行各业中应用广泛 没有什么能逃出你的掌心
大数据特点 数据量大 数据种类多 要求实时性强 主导气质无法掩盖
同时推出大数据hadoop
引领大数据行业风潮
网站后台维护
大型项目必选开发语言
大数据处理服务器开发
金融机构大数据应用
智能家居家电
银行管理系统
真实就业数据 震撼你的小心脏
无论按照工作经验还是市场本身的薪资变化趋势
大数据工程师都是一路高歌猛进,当之无愧的互联网贵族!
市场招聘条件分析
北京大数据工程师就业形势分析:招聘待遇,工资20000-29999占比最多,达35%。经验要求,3-5年工作经验要求的占比最多,达63%;学历要求,本科学历要求的占比最多,达66%。该数据仅供参考
以上数据来自百度搜索
我要入门潮流技能 颠覆性课程
拒绝用老掉牙的淘汰项目练手 要做就做前沿
覆盖大数据行业主流技术岗位,课程半年升级一次,紧跟市场与企业步伐
01 大数据入门基础课程
1.JavaSE
2.MySQL
3.JDBC
4.Linux
5.shell
6.HTML
7.CSS
8.JavaScript
9.JSP
10.Servlet
02 大数据Hadoop基础
1.大数据概论
2.Hadoop框架
3.HDFS分布式文件系统
4.MapReduce计算模型
5.全真实训项目
03 大数据离线分析
1.Hive数据仓库
2.Sqoop ETL工具
3.Azkaban工作流引擎
4.Ooize
5.Impala
6.全真实训项目
04 大数据实时计算
1.Zookeeper分布式协调系统
2.HBase分布式数据库
3.Redis数据库
4.mogDB数据库
5.Kudu列式存储系统
6.Storm实时数据处理平台
7.Kafka分布式发布订阅消息系统
8.Flume海量日志采集系统
9.全真实训综合项目
05 Spark数据计算
1.Scala
2.Spark
3RDD
4.Spark SQL
5. Streaming
6. Mahout
7.MLlib
8.GraphX
9.Spark R
10.Python
11.Alluxio
12.Python爬虫
13.ElasticSearch
14.Lucene
Hadoop基础实战项目
项目名称:搜狗搜索日志分析系统
数据体量:5000W+/日
硬件环境:Hadoop集群 12台
软件环境:Hadoop2.5.2+Hive1.2.1+MR+Oracle10g
项目描述:
搜狗每天产生大量的日志数据,从日志数据里面能提取到有用的数据包括每个用户的ID、浏览次数、月/日浏览频率、访问源、浏览内容等等,提取这些内容、统计数据分析每个用户行为,从而做出有利的决定。
大数据离线实战项目
项目名称:新浪微博数据分析系统
日均数据体量:3GB+
硬件环境:Hadoop集群 50台
软件环境:MapReduce+HBase0.98.9+Storm0.9.6+Hadoop2.5.2+Kafka2.10+Zooke
eper3.4.5+CentOS-6.5-X86
项目描述:
此次项目我们需要处理微博产生的数据,通过对数据的处理得到所需的数据,微博拥有大量的用户,大量的用户潜在的价值是巨大,怎么挖掘这些潜在的宝藏就是我们项目最直接的目的,为了能够实时的进行数据处理使用Storm流式计算系统,和HBase、Zookeeper、Kafka组成框架,对数据进行处理,当然这些都是建立在hadoop集群上实现的,底层的存储还是HDFS。
大数据实时全真项目
项目名称:网络流量流向异常账号统计项目
数据体量:每天1000亿,每秒峰值100 000
硬件环境:Hadoop集群 600台
软件环境:Hadoop2.5.2+Hive1.2.1+MR+Oracle10g
项目描述:
运营商骨干网上采集现网流量流向信息,根据这些原始信息检测账号是否存在异常,如果多个终端使用同一个宽带账号,超过一定阈值则触发报警机制,例如阈值为5时,同一个账号同时连接的终端数量不能超过该值,如果超过则报警。
Spark阶段项目
项目名称:京东网上商城数据统计分析平台
数据体量:5000W+/日
硬件环境:centos-6.5-x86 集群:spark standalone(Master-1,Worker-3)
软件环境:hadoop,spark,hive,mysql,idea,navicat,kafka,flume
每日处理的数据量:3GB
项目描述:
基于京东网上商城数据统计分析平台--该项目采用了目前大数据领域非常流行的技术——Spark。本项目使用了Spark技术生态栈中最常用的三个技术框架,Spark Core、Spark SQL和Spark Streaming,进行离线计算和实时计算业务模块的开发。实现了包括:统计和分析UV、PV、登录、留存、热门商品离线统计、广告流量实时统计3个业务模块。

扫码关注镀金池微信号
手机订课,优惠多多
















